In an enterprise environment, it’s very common to need to insert a lot of data into a relational database. Have you ever faced this? If so, what does “a lot” of data mean to you? How about a million records to insert, for example?
If we use Spring Data JPA and JpaRepository standard methods like saveAll(Iterable<S> entities); and the classic setup @Id @GeneratedValue(strategy = GenerationType.IDENTITY) on our POJO identifier, we may realize that our approach is relatively slow. Reeeaaally slow!
However, there is one even slower way of doing this – writing a method that iterates over a collection and calls the .save(S entity) method from the repository for each item in the collection.
Let’s take a look at some example code (of course, we’d use better business domain names in real-world implementations):
POJO:
@Entity
@NoArgsConstructor
public class Pojo {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String value;
}
POJO service:
@Service
public class PojoInterfaceImpl implements PojoService {
@Autowired
private PojoRepository pojoRepository;
@Override
public void save(List<Pojo> pojos) {
pojos.forEach(pojo -> pojoRepository.save(pojo));
}
@Override
public void saveAll(List<Pojo> pojos) {
pojoRepository.saveAll(pojos);
}
}
POJO repository:
@Repository
public interface PojoRepository extends JpaRepository<Pojo, Long> {
}
As you can see, we’re keeping it “stock” regarding the repository.
If we do a drill-down, we’ll get to the SimpleJpaRepository class and see the methods mentioned above.
@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null!");
List<S> result = new ArrayList<>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
If you look at the overridden saveAll(Iterable<S> entities) method, it does iterate over a collection calling the save(S entity) method for each iteration.
So why is it uber slow when we iterate and save, but when the Spring implementation does it for us, it’s faster?
Notice the very subtle inclusion of @Transactional on the save method? That’s why. When our implementation calls the save(S entity) method in the loop, we create a transaction each and every time we call that method. When we call the saveAll(Iterable<S> entities) method, Spring is smarter and creates only one transaction for the entire process. Transaction creation and management are expensive in terms of performance. If there are a lot of entities in our collection, creating a transaction for each one of them is a big, BIG overhead.
Ok, so let’s see it in practice. First, we’ll add some properties to our application.properties file so we can have a better overview of the events that take place.
spring.jpa.show-sql=true // this will show the sql statements executed
logging.level.org.springframework.orm.jpa=DEBUG // This show the transaction manager activities
spring.jpa.properties.hibernate.generate_statistics=true // This will show some interesting metrics
When we run a test that saves a collection containing three entities (POJOs mentioned above) using the save(S entity) method, we’ll get this console output:
When we run the same kind of test using the saveAll(Iterable<S> entities) method, we’ll get the following:
2022-09-20 10:32:25.510 DEBUG 20189 --- [ main] o.s.orm.jpa.JpaTransactionManager : Creating new transaction with name [org.springframework.data.jpa.repository.support.SimpleJpaRepository.saveAll]: PROPAGATION_REQUIRED,ISOLATION_DEFAULT
2022-09-20 10:32:25.511 DEBUG 20189 --- [ main] o.s.orm.jpa.JpaTransactionManager : Opened new EntityManager [SessionImpl(1832255355<open>)] for JPA transaction
2022-09-20 10:32:25.516 DEBUG 20189 --- [ main] o.s.orm.jpa.JpaTransactionManager : Exposing JPA transaction as JDBC [org.springframework.orm.jpa.vendor.HibernateJpaDialect$HibernateConnectionHandle@6bfdaa7a]
Hibernate: insert into batch_demo.pojo (value) values (?)
Hibernate: insert into batch_demo.pojo (value) values (?)
Hibernate: insert into batch_demo.pojo (value) values (?)
2022-09-20 10:32:25.563 DEBUG 20189 --- [ main] o.s.orm.jpa.JpaTransactionManager : Initiating transaction commit
2022-09-20 10:32:25.563 DEBUG 20189 --- [ main] o.s.orm.jpa.JpaTransactionManager : Committing JPA transaction on EntityManager [SessionImpl(1832255355<open>)]
2022-09-20 10:32:25.580 DEBUG 20189 --- [ main] o.s.orm.jpa.JpaTransactionManager : Closing JPA EntityManager [SessionImpl(1832255355<open>)] after transaction
2022-09-20 10:32:25.581 INFO 20189 --- [ main] i.StatisticalLoggingSessionEventListener : Session Metrics {
511193 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
2952790 nanoseconds spent preparing 3 JDBC statements;
3282622 nanoseconds spent executing 3 JDBC statements;
0 nanoseconds spent executing 0 JDBC batches;
0 nanoseconds spent performing 0 L2C puts;
0 nanoseconds spent performing 0 L2C hits;
0 nanoseconds spent performing 0 L2C misses;
6067268 nanoseconds spent executing 1 flushes (flushing a total of 3 entities and 0 collections);
0 nanoseconds spent executing 0 partial-flushes (flushing a total of 0 entities and 0 collections)
}
As we can see, there is a big difference in what is going on. In the first test, the logs confirm that we have a unique transaction for each insert statement, and we are opening and closing a DB connection three times. But, the Transaction and DB Connection are only created once in the second test. The difference will be even more apparent when we see some performance test results later.
Now that we got that out of the way, and know how saveAll(Iterable<S> entities) behaves, let’s see how we can further improve our simple setup because it is nowhere near good enough if we want to persist a lot of entities efficiently.
So the next evolution is to start using batch (bulk) inserts. With batched inserts, Spring will still create a single transaction, BUT the insert statements will not be sent one by one to the DB server for execution. Instead, they are grouped into batches of configurable batch size and then sent to the DB server for execution as a group (less frequent communication with the DB server, which is good). To summarize, batching allows us to send a group of SQL statements to the database in a single network call. This way, we can optimize our application’s network and memory usage.
In order to do batch inserts, we need to modify our setup a little bit:
POJO:
@Entity
@NoArgsConstructor
public class Pojo {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "pojo_id_seq")
@SequenceGenerator(name = "pojo_id_seq", sequenceName = "pojo_id_seq", allocationSize = 3)
private Long id;
private String value;
}
We also add another property to our application.properties file:
spring.jpa.properties.hibernate.jdbc.batch_size=3 // Controls the maximum size of each batch Hibernate will batch together before asking the driver to execute the batch. Zero or a negative number in this property will disable this feature.
Now, we are still using the saveAll(Iterable<S> entities) method from the SimpleJpaRepository; however, the behavior will be different.
Let’s persist three items again and explain what happens.
There are two select statements and three insert statements. Hibernate statistics states that it has prepared three statements and executed two statements in one batch. That means that these three insert statements have been sent as a batch to the DB server within a single network call.
So why is Spring using two select statements? Because it is querying the sequencer for free IDs that can be assigned to our POJOs. The number of these calls is directly affected by the “allocationSize” parameter in the @SequenceGenerator annotation. We are storing three objects, and our allocationSize is configured to 3, and our batch size is set to 3 in our application properties.
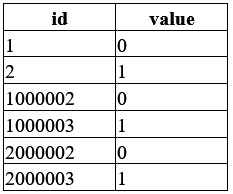
Spring framework will, by default, query the sequencer and get the sequence of IDs needed to store the items, but it will also pre-fetch the next sequence of available IDs and cache them, so next time we try to persist some items we already have a list of identifiers, in which case Spring won’t have to query the sequencer that time; this behavior can also be controlled by creating a sequencer manually and defining its behavior more precisely. However, there is a downside to pre-fetching/caching the sequencer IDs. For example, if our server restarts, our cached (unused IDs) will be lost forever as they’ve already been pulled from the sequencer but never allocated to a record in the database. So, you may find it tempting to set a big allocationSize and have a lot of IDs in the cache, so we don’t waste as much time on select statements that query the sequencer. Let’s say we do that, and set our allocationSize to a really large value like 1,000,000 (1 million), and then persist a relatively low number of items and restart our server too often. Our “pojo” table might end up looking like this.
As we can see, there is a big gap, and a lot of identifiers are being “wasted.” And over time, we could run into issues and even use up our sequencer a lot faster than we expect.
Another performance gain that is also a potential pitfall can be seen in the spring.jpa.properties.hibernate.jdbc.batch_size property we set earlier. If we set a small value (along with the small allocationSize value) we could end up having worse performance because of the large overhead. This is because small batch sizes can result in too many batches, and batch preparation also impacts performance. If we set the batch size too big and then try to store large data objects, we could potentially encounter OutOfMemoryException issues. The reason for the latter is the fact that all entities that we wish to persist will first be stored in memory in the persistence context by Hibernate.
Ok, so now that we’ve discussed some of these tuning considerations, we are ready to look into some performance metrics. But first, let’s walk through the scenario. If we wish to store a hundred entities without batch-ing, then one transaction will be created, and 100 insert statements will be sent one by one to the DB server. However, if we use batching and set batch size to 10 and allocationSize to 10, we’ll have 11 select statements and 10 batch inserts. That is almost five times fewer network calls to the DB server (100 / (11+10) = 4.76). If we scale it up, the difference becomes even more obvious.
Let’s see how it translates to real-world performance comparison. For this use case to insert “a lot” of data, we will persist a million records using different combinations of allocationsSize and batch size parameters.
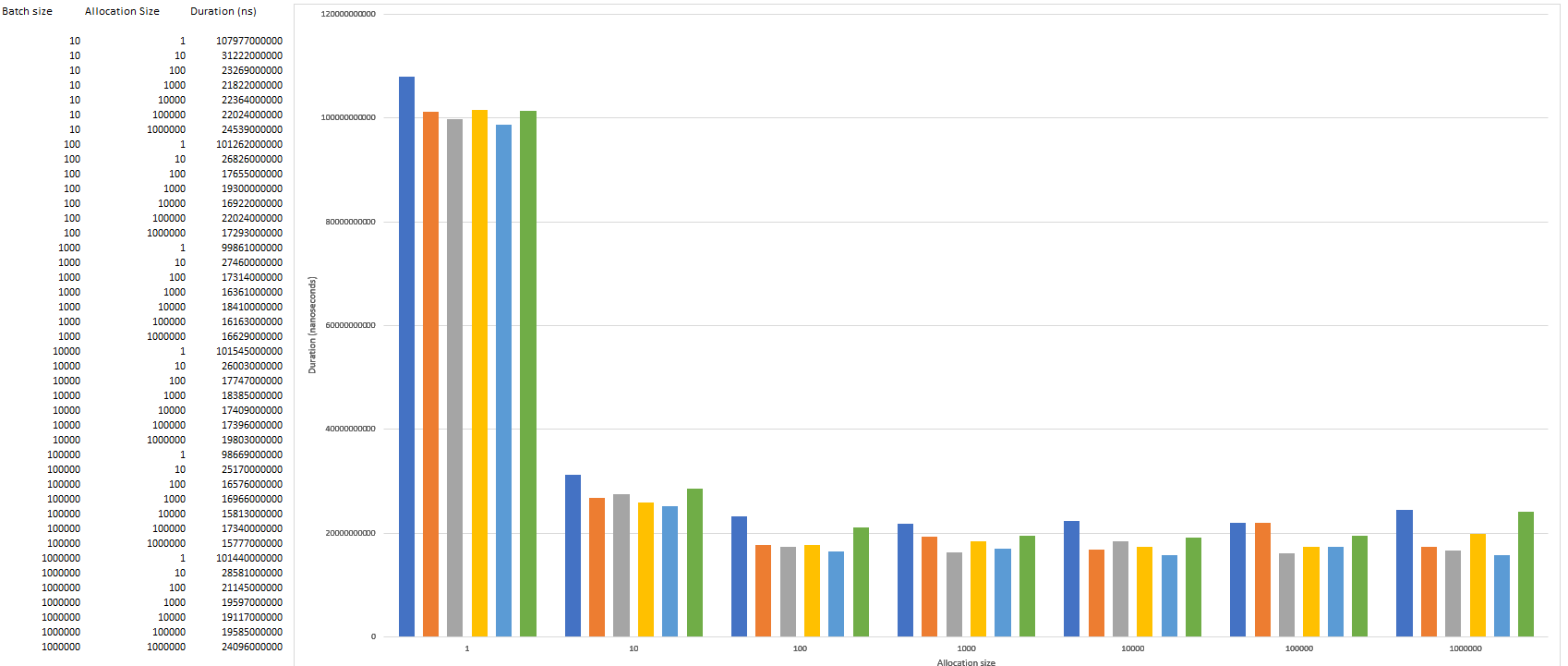
Here is a chart showing our raw results:
The fastest times we got inserting a million simple objects into the DB is 15.78 seconds (15777000000 nanoseconds) using allocationSize = 1000000, batch_size = 100000. We then achieved 15.81 seconds (15813000000 nanoseconds) using allocaitonSize = 10000, batch_size = 100000. As we mentioned, large numbers for these settings do mean speed, but they also come with some non-trivial risks (e.g., memory consumption, loss of identifiers, etc.).
If we compare our fastest time to the time we got with saveAll(Iterable<S> entities) method without batching, which took 2.06 minutes (123.66 seconds; 123656000000 nanoseconds), we can see that we have persisted the data almost 8X faster.
And finally, if we compare our fastest time to the most painful method where we iterate and use save(S entity) -- with inefficient Transaction handling —that it took 8.98 minutes (538.66 seconds; 538656000000 nanoseconds), we see that we have persisted the data roughly 34X faster.
In this simple performance comparison, we have used a large number of small objects on a local machine (application and database server running on my laptop). When we also factor in that objects may carry a lot of information (large memory footprint), that the database and application servers may be geographically distant (latency), and that specific database and application server settings and resource limitations may vary, our parameters and how we tune them begin to carry MUCH more weight.
In our tests, our database server is powerful enough, with low latency, so 100, 10,000, or even 1,000,000 of these small POJOs isn’t a large factor, as can be seen in our chart. The insert time doesn’t change dramatically. The biggest performance gain in our tests was achieved when we simply reduced the number of network calls to the DB. However, if we were to put more strain on our system, we would likely have seen more drastic results. But then again, it may be the other way around in some other environments.
Conclusion:
We have seen drastic changes in performance just by changing two basic parameters. Picking extreme settings is usually not the best approach. When the performance of batch inserting is needed, you should start with moderate values for “batch_size” and “allocationSize” and then adjust up or down as necessary to find the best balance – a valid starting point might be 10 & 10 or 100 & 100. Based on the type of data we are inserting, frequency, server resources, and overall architecture, the settings that show significant performance gain should become clear after a bit of testing and tuning. And with that, I’ll mention that there are even still more ways to tune and optimize batch inserts to an even higher degree, but we’ll save that for another day.
This website uses cookies to ensure proper website functionality and to analyze traffic on our website. These cookies help us understand how visitors interact with our pages so we can continuously improve our services.