DXA 2.2 Series - Dissecting the R2 Data Model - Part 1
Atila Sos
| Certified RWS Tridion architect and RWS Tridion MVP
|
As mentioned in my previous post, I shall be writing a series of blogs dedicated to DXA 2.2, but before diving in, just an FYI. As I’m predominantly a .NET developer, all examples will be given in C#. You can use the described examples and techniques in Java as well with some slight changes due to differences in technology and syntax, but for the most part, the same principles do apply.
Introduction
This is the first entry in my DXA 2.2 series in which I shall take a closer look at the R2 Data Model. ‘Why bother with such a topic?’ one might ask, and he’d be right. Having knowledge about the Model is not a must, as you could easily start working with DXA without understanding it, however, being familiar with the Model does have its merits. If you run into any issues with your View Models for example, a quick look at the CMS Template generated output can give you loads of information if you know what to pay attention to.
History
Prior to DXA 2.0, the data model used by the framework was DD4T, which for all intents and purposes did get the job done, but it had some flaws. The biggest one was that it was way too verbose. You would end up with huge chunks of published data, some of which was not necessarily needed. This was especially pronounced when DD4T XML was used. Switching to JSON down the lane did help somewhat in reducing the published data’s size, but you could only accomplish so much without restructuring the data. Also, the DD4T data was more closely related to the CM domain’s side and didn’t always make sense from the Presentation’s (website’s) perspective. Because of these reasons, it was decided to design and use a new data model called “R2”. The switch to the new Model was carried out in DXA 2.0 and it’s still used nowadays.
For completeness’ sake, I must point out that the DD4T model is still supported by DXA, however using R2 should be the way forward. That is, if you want to leverage its advantages.
R2 Data Model structure
The easiest way to illustrate the data structure is through examples. I will start with the simplest one where I will explain all properties, and then slowly add complexity. Each time I do, I will highlight what has changed and other important details.
The examples:
Are the result of previewing a CT or PT in the CME
Have a list of Tridion items used. Those Tridion items will also be documented so that you can easily recreate them in your own environment if you wish to play around
Can also use Tridion items of previous examples
Will utilize the native Regions introduced in SDL Sites 9.0
Will have a screenshot of their JSON structure (the data is formatted by Notepad++’s ‘JSON Viewer’ plugin) accompanied by explanation and comments.
Example 0 – Empty Page
The first example is the simplest one consisting of an empty Page (no Component Presentations), with no Includes defined by the Page Template and no Metadata or nested Regions defined by the Page Schema.
Tridion items used:
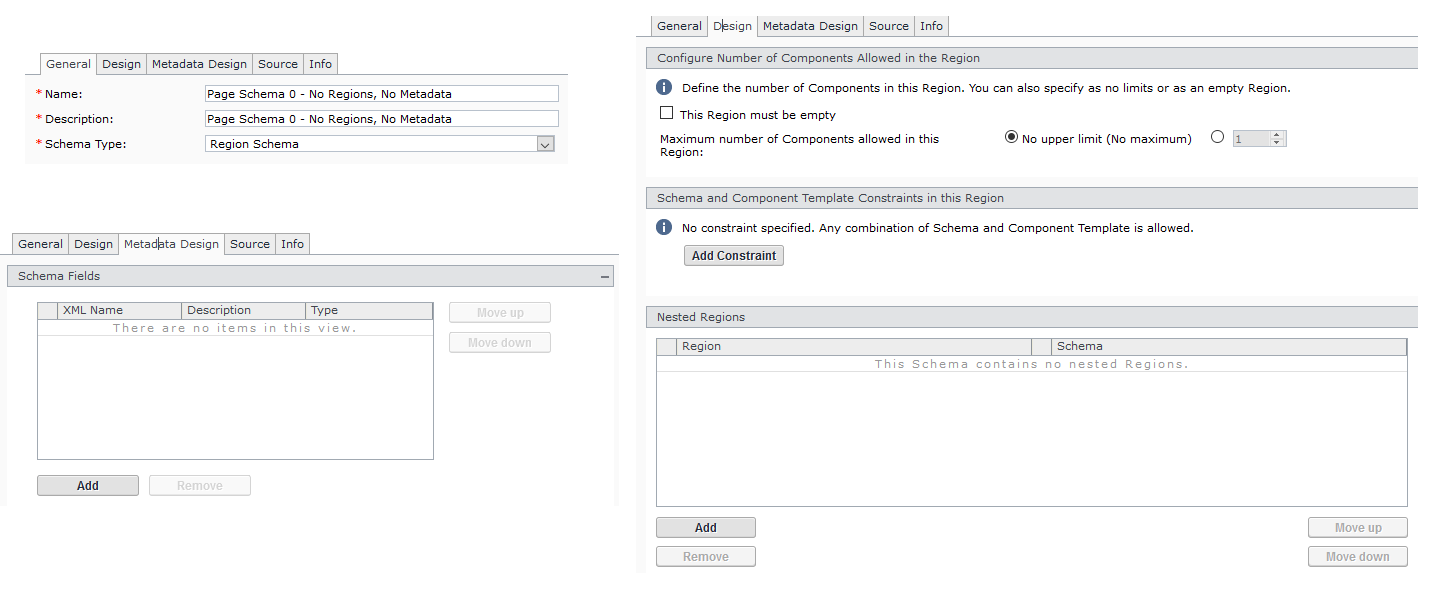
Item Type: Region Schema (used as Page Schema)
Name: Page Schema 0 - No Regions, No Metadata
Design: Empty (No Constraints and no Nested Regions)
Metadata Design: Empty
Page Schema
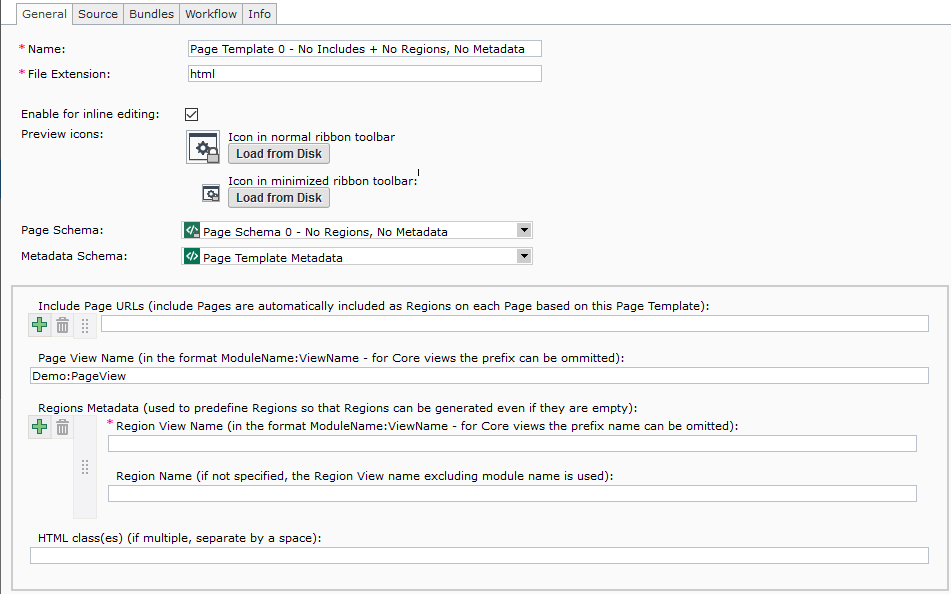
Item Type: Page Template
Name: Page Template 0 - No Includes + No Regions, No Metadata
Page Schema: Page Schema 0 - No Regions, No Metadata
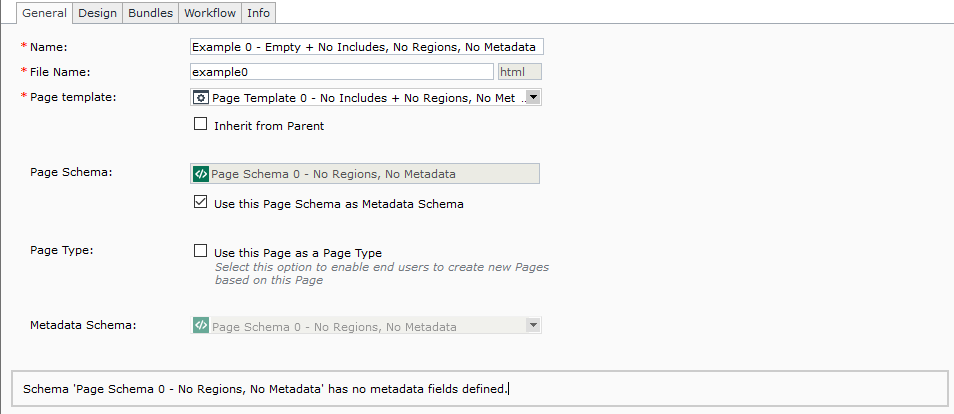
Name: Example 0 - Empty + No Includes, No Regions, No Metadata
Metadata: No
Component Presentations: No
Page
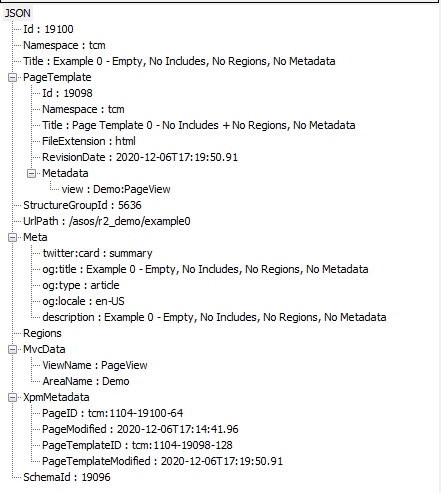
Resulting JSON:
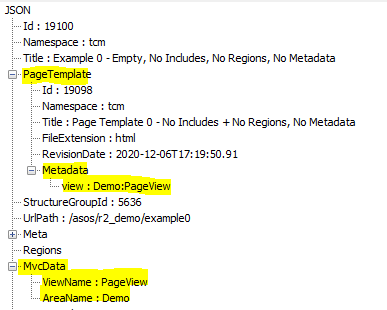
The resulting (formatted) JSON is below:
Resulting JSON
Breakdown:
The JSON always starts with the “Id“ of the item. If the item is a Page like in this example, this will be a simple number. If the item is a Dynamic Component Presentation (DCP), the Id will be different (more on this in one of the later examples).
The “Id“ is followed by the “Namespace“, in this case ‘tcm’, indicating that the item in question is from Tridion Sites. The “Namespace“ is followed by the item’s “Title“.
JSON fragment 1 - Generic Properties
These properties are then followed by a nested property which describes the Template. For Pages, this property is “PageTemplate”. For DCPs it will be different with different nested properties (more on this in one of the later examples).
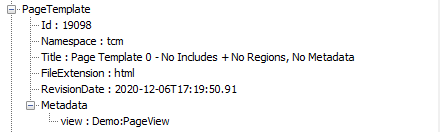
The “PageTemplate”, like the main item. again has the same basic information listed like “Id“, “Namespace“, “Title“. This is followed by the extension of the Template written in the property “FileExtension” and the “RevisionDate” which is basically the ‘modified date’. The final property is the “Metadata” of the Page Template which contains important information for the framework.
JSON fragment 2 - Template
The ”PageTemplate” is followed by additional properties describing the original item. This is another place where the JSON structure differs for non-pages. For Pages, these are information about the Structure Group Id and the url of the Page contained within the “StructureGroupId” and “UrlPath” properties, respectively.
JSON fragment 3 - Page Specific Properties
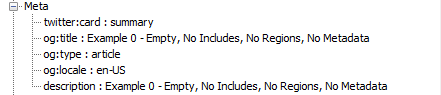
The next property, “Meta” is a strange one that only appears for Pages. If the Page contains any, it will hold the Page’s metadata (though the metadata also has a distinct property, but more on that in a later example). Do note that even though no metadata was set on the Page, some values are still appearing. These are built into the DXA (CM) Templating code and personally I almost never use them.
JSON fragment 4 - Page Meta
Unlike the previous property which you can ignore in most cases, the following one is very important. It’s called “Regions” and in this example it’s empty (an empty array), but otherwise it would hold all the Page’s Regions and their Component Presentations. Again, will be shown in future examples.
JSON fragment 5 - Page Regions
The next property is also an essential part of the Framework. The data contained within the “MvcData” is what dictates the inner routing of DXA (Pages/Regions/Entities) and is something which is also used by the built-in HTML helpers (ie. Html.DxaRegions(), HtmlDxaEntities(), etc.). This data is generated based on the Template metadata (PT or CT), though there is one exception which will be covered in due time, that is you might have guessed so far, by a different example :).
JSON fragment 6 - Mvc Data
JSON fragment 7 - Relation between the Template Metadata and MvcData
The “MvcData” is followed by “XpmMetadata“ which contains nested properties all related to Experience Manager. These properties are for example used by the built-in HTML helpers (ie. Html.DxaEntityMarkup() Html.DxaPageMarkup(), etc.).
JSON fragment 8 - Xpm Metadata
And last but not least, the final property is “Schema” which contains the Id of the Page or Content Schema, depending on the item type.
JSON fragment 9 - Id Property
Conclusion
In this first entry I have given a short history about R2, defined how I will explain the Model through examples, given a simple example and illustrated some of the basics of the R2 Data Model. In the following blog entries, I will continue with the examples by adding more and more scenarios and highlighting how the resulting JSON changes and some other additional information.
I hope that my envisioned way of explaining the structure is easily understandable. As always, if you have any questions, please don’t hesitate to get in touch.
This website uses cookies to ensure proper website functionality and to analyze traffic on our website. These cookies help us understand how visitors interact with our pages so we can continuously improve our services.